My family is spread out across the country — from Charlotte, North Carolina to Wooster, Ohio to Seattle, Washington. Three distinct geographic locations in which people use different vernacular to express themselves — everything from the strip of land between the sidewalk and the street (A tree lawn of course!) to the carbonated beverages we drink (I still hold onto my Midwestern use of “pop”) to that big mountain cat that lives in the foothills of the Cascades (a cougar, not a panther, catamount or mountain lion).
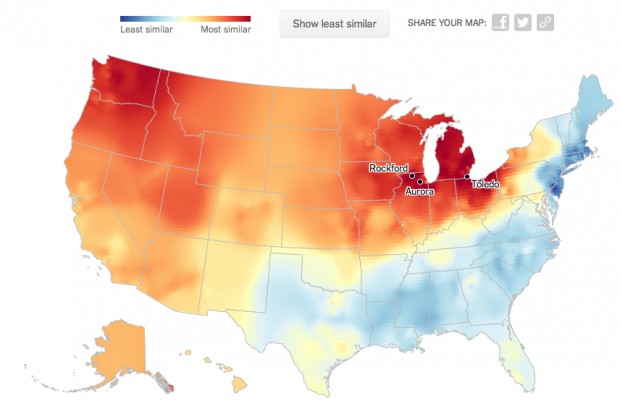
 So, you can imagine the fun our family had over the holiday when we all took the amazing dialect quiz on The New York Times, which pinpoints where people share common language. My top three cities initially came in as Seattle, Spokane and Lincoln, Nebraska — an interesting analysis since it skewed more towards the west coast where I’ve lived since 1995 than my hometown in Ohio. (My second analysis, shown above, skewed a bit more Midwestern). Our family had a few laughs when my dad — a life long Buckeye — took the quiz and was pinpointed as most like Akron, Cleveland and Toledo. Amazingly accurate!
So, you can imagine the fun our family had over the holiday when we all took the amazing dialect quiz on The New York Times, which pinpoints where people share common language. My top three cities initially came in as Seattle, Spokane and Lincoln, Nebraska — an interesting analysis since it skewed more towards the west coast where I’ve lived since 1995 than my hometown in Ohio. (My second analysis, shown above, skewed a bit more Midwestern). Our family had a few laughs when my dad — a life long Buckeye — took the quiz and was pinpointed as most like Akron, Cleveland and Toledo. Amazingly accurate!
The questions in the NY Times quiz are based on a linguistics project started more than a decade ago at Harvard University by Bert Vaux and Scott Golder.

Interestingly, Golder is now an employee at Context Relevant, a Seattle big data startup backed by Madrona and Bloomberg that’s developing tools to analyze massive amounts of data. Golder started working on a web-based version of the linguistics survey as a data collection tool in 2001 while an undergraduate at Harvard. Prior to the Internet, Golder said that language data had been collected in a traditional manner, in which researchers painstakingly interviewed and recorded small numbers of people.
“Remember that in 2001, the consumer Internet was still in its infancy, and “viral” hadn’t been invented yet — we considered getting 50,000 respondents as a massive victory,” Golder tells GeekWire. “It wasn’t called Big Data back then, but that’s essentially what it was. I realized even then that the Internet presented an enormous opportunity to study human behavior at massive scale, with high fidelity, and at low cost.”
Golder, who in addition to working at Context Relevant is a PhD candidate in Sociology at Cornell University, said the Harvard study has experienced an amazing resurgence.
“An enterprising statistics student updated the maps using current graphics tools, and it has spread like wildfire through Facebook and other social media. I think the reason is that people love learning more about themselves, and seeing how they’re similar to or different from others,” said Golder, who recently moved to Seattle to work at Context Relevant and says that he’s constantly on the lookout for interesting dialect unique to the Northwest.
“My main agenda in working on the project was advancing the use of the Internet as a data collection tool,” said Golder of his work on the project in 2001. “I was able to collect 1000x the data that would have been possible using traditional methods.”
If you are looking for a little fun before the end of the year, make sure to take the quiz and let us know where your dialect is strongest.
Meanwhile, here’s Golder talking about the concept on the Today show.
Visit NBCNews.com for breaking news, world news, and news about the economy



